

分散式驗證框架:數位世界的「身分」到底是什麼
Proof, not profile:讓權利與授權回到身分核心

/ 撰文者:劉維人

引言
無論數位世界或物理世界,權利(Rights)都依附於身分(Identity)。在數位世界,使用者需要識別身分,或獲得存取權,才能行使自己的權利。
同理,如果要檢查權利是否被侵害,也需要得知被侵害者是誰;或者檢查哪些原本可以行使的權利,變得不再完整。
「身分」這個概念包含很多層次,例如主體與其他人之間的關係、主體的自我認同、主體具備的各種資格。
在數位世界會使用到「身分」的脈絡,主要在於防止冒用,以及查驗屬性。例如銀行開戶需要上傳駕照或身分證、購物與觀看網站檢查是否成年、申請補助檢查社會保險號碼或身分證字號、社群平台要求實名認證。
目前的狀況:集中式身分
上述的「數位身分」(Digital Identity) 大多以證件或帳號(Account)方式存在。前者諸如身分證或身分證、駕照、或者某些國家的手機號碼。後者諸如社群平台的帳號、apple 或 google 的帳號。這兩類身分都由政府或大型企業發行,我們在這些機構登記(Enroll)自己的資料,由機構確認真實性之後,將證件或帳號發給我們。我們之後再用這些證件或帳號登入其他服務,或者在其他地方證明我們是誰。
這種框架稱為集中式身分(Centralized Identity)。證明身分的證據,是這些身分提供者(Identity Provider, IdP)發行的信物。信物上往往帶有穩定的識別符(Identifiers),每個識別符綁定一個人。
這樣的設計產生以下問題:
使用者仰賴 IdP 發行的信物,證明自己是誰。當 IdP 不當限制信物的使用,或者 IdP 故障、被駭入時,使用者的相關權利直接被侵蝕。例如當社群平台當機或錯誤停權你的帳號,你無法聯絡親友、無法存取其他服務、無法存取屬於你的線上檔案。
穩定的識別符成為追蹤、監控、偽造身分的破口。在不斷用同一個識別符或信物來識別身分的過程中,這個識別符就不斷出現在各種交易紀錄、身分檔案中。惡意使用者只要找到這個識別符,就能立刻將好幾份資料碎片,重組成我們的完整個資。值得注意的是,這項風險無法光靠使用假名緩解。只要用識別符來識別身分,並記錄在檔案中,無論你自稱張三還是李四都沒有影響。
某些身分信物相當權威,例如社會保險卡、駕照,被社會上各產業廣泛用來查驗身分與資格。查驗時為確保這類證件為真,通常會索取整張證件,比對各種細節。但在數位世界,這使得證件中的資訊更容易外洩。
會出現這些問題的主因,就是證件或信物上匯集了太多資訊。同一份證件上記錄了好幾種不同的資訊,同一枚識別符連結了太多不同資料,用來檢查好幾種不同的資格。檢查紀錄累積越多,能夠追蹤到使用者就越容易,使用者也就越仰賴那個信物或識別符。
我們真的需要權威證件嗎?
因此,要避免上述問題的方法之一,就是盡量讓每一次驗證,都只獲取驗證所必需的資訊。
其實絕大多數的驗證都有明確目標:是否具備駕車資格、是否對某種藥物過敏、是否具備一定存款、從哪個科系畢業。這些驗證目標都是使用者的「屬性」(Attributes)。
另外一些驗證目標則是「符節」(Credentials):簡訊 OTP 中的密碼、機器授權時的 API 金鑰、車票、訪客證、以及物理世界的鑰匙。用這些物件或資料結構來開啟閘門,或給予存取權。
為了防止冒用,上述兩類目標經常會綁定使用者。但綁定是為了確保使用者的同一性,而非為了得知使用者的更多資訊。銀行開戶之所以需要檢查很多證件與條件,是為了確保你不是詐騙者、你有收入、你能償還貸款,不是為了瞭解你祖宗十八代。
因此,如果能夠將證明文件與信物,盡量回歸到「證明屬性為真」或「證明符節為真」的本質,盡量不包含其他資訊,那麼集中式身分架構造成的問題,就能大幅減輕。
要證明屬性或符節為真,信物上只需要紀載兩條資訊,並具備一項特質。兩條資訊分別是:
屬性本身
屬性的出處
而要具備的一項特質則是:
資訊在撰寫時與讀取時相同
舉例來說,要檢查你是否對 Y 藥物過敏,只需要「OO 醫事機構」出具一份證據,寫著「你對 Y 藥物過敏」即可。若要防止你偽造過敏證明,可以在過敏證明書上蓋鋼印,或者在驗證時打個電話向 OO 醫事機構確認。
過敏證明書上,根本不需要寫你的姓名、住址、電話、緊急聯絡人。雖然醫院在檢查過敏史的時候,通常會需要檢查這些資訊,但每項檢查可以獨立進行,並且每項屬性都記載在不同的證據上,並不需要記錄在同一份表單或證件上,而且沒有任何一項證據需要記載你的健保卡號碼。
數位世界的身分證據,需要記名嗎?
這暗示一件有趣的事情:信物未必需要記名。
而且不只是信物,大部分用來證明我們具備某些屬性與資格的證據,都不需要記名,只需要確認證據為真即可。目前查驗證件之所以需要比對名字,主要是為了避免證件冒用。
物理世界極難克服冒用問題,因為「證據」跟「持有證據」兩個概念彼此獨立,而物理世界幾乎無法防止證據換手持有。即使把證據上鎖,鑰匙或密碼也可以交給別人使用。因此物理世界只好在檢查證據時,一併檢查持有者。常見的方法就是利用另一張難以仿製的權威證件,比對證件上的名字與照片。這張既有名字又有照片的證件,就是許多國家都會有的權威證件。這種比對方法,正是集中式身分的起源。
但進入數位時代之後,開始出現一些方法,能有效將證據綁定在某人身上,從根本避免冒用問題。例如非對稱加密(Asymmetric Encryption)可以將證據綁定指定的操作程序;生物辨識(Biometrics)則能將操作程序綁定使用者的身體。結合這些技術,就能確保證據只有申請者能夠開啟,出示證據的人就是最初申請證據的人。如此一來,證據本身就不需要記名。
這些科技的出現,加上數位世界的「存取即複製」特性(物理世界檢查證件時,通常不要求影印。但在數位世界,只要能存取到證件資訊,就一定可以把證件上的資訊複製下來),使人們注意到集中式身分的缺點,並開始倡議「分散式驗證」(Decentralized Authentication)框架。
在「分散式驗證」框架下,「出示證據證明資格與屬性」和「使用者是誰」是兩個完全獨立的程序:如果你需要證明自己具備某些屬性,就向相關機構申請證據,並在檢查時出示。
至於你是誰?跟整段程序完全無關。你從發證機構(又稱發證者,issuer)拿到證據之後,就放進加密保護的軟硬體中,確保只有你可以存取。因此,查驗你是否具備資格的機構(又稱驗證者,verifier)不需要擔心你冒用證據,證據上也就不需要紀載姓名、照片等物理證件常有的個人資訊。
因此,再也不需要任何一張權威證件,統合你的所有重要資訊。權威證件消失,「發行權威證件的機關」,也就是 IdP,也就跟著消失。你想證明自己具備哪些屬性,就向相應機構申請。每個人都各自從不同發證者,申請很多份不同類型的證據,用於通過不同驗證。
其實這與目前狀況沒有差很多。你的財務狀況證據,幾乎都是金融機構發行的,不會寫在身分證、社會保險卡、駕照上,對吧?分散式驗證框架,只是讓「一張證件能夠代表你」的事情消失。
一旦不需要「權威證件」,每份證據被重複使用的次數就會大幅減少,因為不同驗證場景會開始使用不同證據。這麼一來,就更不容易從驗證紀錄拼湊出完整的使用者身分,或者藉此追蹤使用者。
最後,這種架構還有一個優點:既然證據裝在加密保護的軟硬體中,只有你本人能夠打開。所有證據的出示都需要你的同意,能夠明顯減少「偷印證件」這類未經同意使用個資的問題。
資料最小化的三個層次
風險分散、防止追蹤、確保使用者同意,聽起來相當好。但這種框架需要許多配套條件。各元件的共通原則,就是資料最小化 (Data Minimization)。
既然防止追蹤的根本方法,是防止足跡的串接,根本方式就是減少能夠串接的足跡數量,以及減少每份足跡中能用來串接的線索。兩種原理的共通概念,就是「驗證過程中留下的資訊越少越好」。最理想的狀況,就是除了確保驗證有效的資訊之外,完全不釋出任何資訊。
舉例來說,如果要檢查購買菸酒的人是否成年,釋出的資訊就只有「成年」,不包括精確的出生年月日,當然也不包含姓名、證件號碼、設備識別碼、IP。如果要發放育兒補貼,釋出的資訊就只有「育有幼兒」以及「申請者尚未領取本次補貼」,不包括申請者與幼兒的身分、收入、地址等資料,或設備的識別碼與 IP。
然而,資料最小化要減少的目標,不只是「直接被讀取的資訊」,也包含「識別資訊的標記」以及「資訊曾經被傳輸過的事實」。
以上述的「成年」和「育兒津貼」驗證為例,最直觀的資料最小化方法,就是讓使用者傳出的資訊,與驗證者詢問的資訊完全相同,或者只傳送「yes/no」,不傳送任何其他資訊。這種方法就是當代所謂的「零知識證明」(Zero Knowledge Proof, ZKP)(筆者其實認為稱之「零洩密證明」更為精確)。
但零知識證明並不能消除驗證中所有不必要的資訊,因為驗證者依然可以詢問大量資訊(詳情建議參閱 EFF 的這篇文章)。此外,「資訊從哪裡傳到哪裡」,也就是發信方與收信方的識別線索,發信與收信方的數位位址、發信與收信方設備的物理所在地,以及通訊過程中經過的各個節點,也是一種資訊。這些資訊同樣可以用來追蹤,用來重組數位足跡,故同樣需要盡量減少。
減少後面這種資訊的方法,可以粗分為兩種:使同一個發信方有一大堆不同名字(混亂識別資訊的標記),以及直接盡量減少資訊的傳輸。
在網路通訊中,為了使每一台設備能夠順利解析資訊,設備都會有識別符,也難以避免惡意蒐集。為了盡量防止追蹤,就有人想到製造大量的 Identifier,防止證據與使用者一一對應,例如讓使用者端的程式自己生成識別符,並且可以不斷更換。實作方法包括「匿名憑證」(Anonymous Credential)或「孤域印」(Pairwise Pseudonym Identifier, PPID,即每種服務域各自不同,阻止跨域連結的識別方式)。
很多旅館為了防止賊人開門,即使房客使用同一張房卡,密碼仍會每天更換。數位皮夾也應該採取同樣原理,在地端生成許多識別符,讓每一張證明文件上面的識別符都盡量不一樣,藉此妨礙追蹤。並且淘汰時間過久的識別符,以新的識別符來標示自己,以新的識別符連結同一份證明文件。
除了使同一個發信方有一大堆不同名字以外,另一個更根本的防止洩漏資訊方法,就是盡量減少資訊的傳輸。畢竟通訊設備、IP 等工具都會留下足跡,成為身分重組的線索。光是消除證據上的識別符( Iidentifier) 並不能真正防止身分重組與追蹤,盡量減少通訊次數,才能確實提高重組難度。
其中一種常見的架構,就是數位身分自主(Self-Sovereign Identity,SSI)。它使證據從發行到驗證的資訊流動是單向的。發行會員卡、駕照、過敏證明的單位,在發行這些證據之後,就無法從這些證據上、從證據持有者的設備上、或者檢核這些證據的驗證方,收到任何資訊。發證方無法知道證據被誰驗證,證據上的資訊被誰讀取。藉此防止驗證方與持有者的數位足跡,回傳到發證方,引發潛在的數位追蹤。
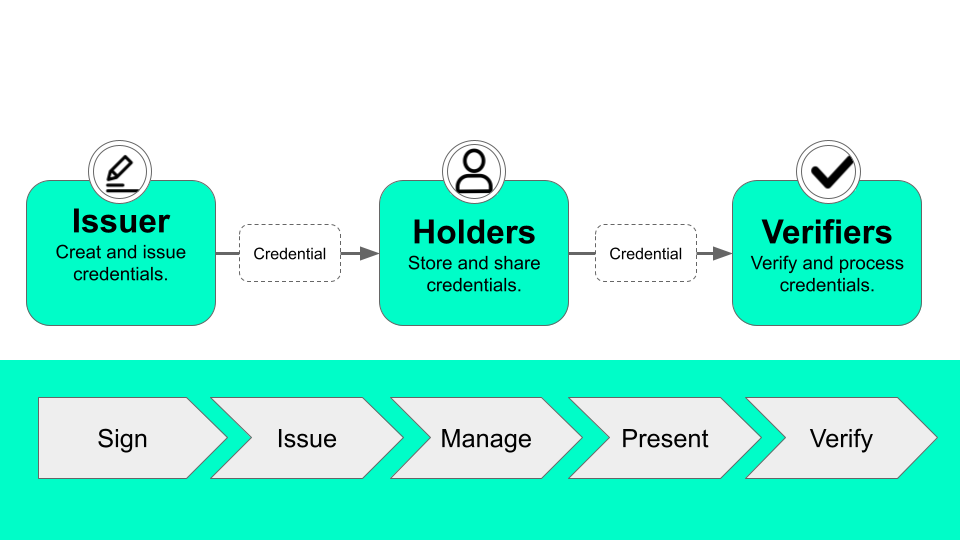
除了避免驗證足跡回傳到發證方,另一項減少通訊的方式就是離線驗證(Offline Authentication)。因為使用者與驗證者的 IP 與位址都是可以用來追蹤的線索,而在驗證過程中不上網,至少可以減少這類線索的釋出。這在離線驗證能夠實行的脈絡特別重要,因為離線驗證的實現,意味著使用者與驗證者共處同一物理空間,為了盡量避免該物理空間的資訊洩漏,只要能夠離線驗證的,就應該預設成離線驗證。
註:上述幾項條件,在 epicenter.works 發表的數位隱私觀察簡介〈Privacy in Digital Public Infrastructure〉中都有更詳盡的敘述。如果要進一步了解分散式驗證框架應該落實哪些條件才能如何保障隱私、防止數位追蹤,非常建議閱讀這篇文章。資料集中的隱憂
然而,即使達成了資料最小化,如果通訊紀錄集中到少數幾個節點,節點就能夠從記錄之間的相關性,拼湊出整份拼圖。因此,集中式節點,也就是同時從多個來源獲得資訊與數位足跡的節點,是分散式驗證的天敵。舉例來說,如果同一個技術提供者,同時幫多個組織,發行證據給同一個使用者;或者同時幫多個驗證者,檢查同一位使用者的資格,使用者的記錄就會自然而然集中在這個技術提供者上,即使能夠猜到多份紀錄來自同一個人。
但服務與信任,天生就有集中化的傾向。避免資訊的重新集中(Recentralization),是最困難的。可能的方式之一,是要求證據的發行方、驗證方、以及各種信任服務的提供者,都負擔完全的責任,不因委託第三方進行工作或採購外部工具而減輕。同時鼓勵新興驗證工具與驗證技術自由競爭,防止少數廠商從各方承攬工作。
小結
上述的證據分散,可以使身分與個資的所有權與掌控權,盡量回到使用者手中,減少被特定證件、帳號、發證機關掌控。而各種資料最小化方案,則能盡量防止資料的追蹤與重新連結。防止身分被追蹤、隱私被洩漏。在數位化程度快速提高,數位權利的需求急速飆升的當下,這些讓使用者能夠盡量行使數位權利的架構,已經受到許多國家的採用 (例如歐盟的身分法案 eIDAS 便是奠基在此架構上)。
然而,由於這套架構必須將目前集中的個資與身分資訊,分散到各方處理。在控管、權責區分、稽核與監理上,都需要大幅變動。此外,這套架構要能安全地落實,需要許多新技術,其中某些技術都還在研發階段。故討論這套架構時,必須在預期效果、需求真實度、架構合理性、技術成熟度、利害相關方、規範與治理衝擊等面向上,每一層都盡量明確地定義與討論,才能避免淪為空談。
👾
衍伸閱讀
Alexis Hancock: “Zero Knowledge Proofs Alone Are Not a Digital ID Solution to Protecting User Privacy”, Electronic Frontier Foundation, 2025/07/25.